Google Cloud Dataflow is a fully-managed service for executing Apache Beam pipelines within the Google Cloud Platform(GCP). In a recent blog post, Google announced a new, more services-based architecture called Runner v2 to Dataflow – which will include multi-language support for all of its language SDKs.
The company redesigned the Dataflow runner for Apache Beam in a second version, offering:
- Multi-language support
- Increased parity across SDKs, including state and timer support in Python
- More I/O’s for Python developers using the cross-language framework, including Kafka I/O
- Custom container support
- Increased throughput using SplittableDoFns
- Improved performance
With the multi-language support, development teams can share components within their organization written in their preferred language and weave them into a single, high-performance, distributed processing pipeline, Google stated in the blog post. Before the second version of Runner, this was not possible.
Runner V2 has a more efficient and portable worker architecture rewritten in C++, which is based on Apache Beam’s new portability framework. Moreover, Google packaged this framework together with Dataflow Shuffle for batch jobs and Streaming Engine for streaming jobs, allowing them to provide a standard feature set from now on across all language-specific SDKs, as well as share bug fixes and performance improvements. The critical component in the architecture is the worker Virtual Machines (VM), which run the entire pipeline and have access to the various SDKs.
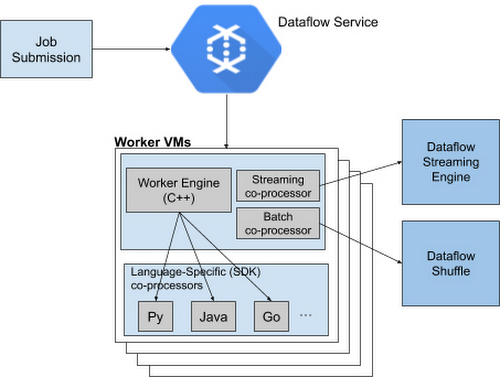
Source: https://cloud.google.com/blog/products/data-analytics/multi-language-sdks-for-building-cloud-pipelines
Harsh Vardhan and Chamikara Jayalath, both software engineers at Google, wrote in the blog post:
If features or transforms are missing for a given language, they must be duplicated across various SDKs to ensure parity; otherwise, there will be gaps in feature coverage and newer SDKs like Apache Beam Go SDK will support fewer features and exhibit inferior performance characteristics for some scenarios.
Currently, Dataflow Runner v2 is available with Python streaming pipelines and Google recommends developers to test the new Runner out with current non-production workloads before enabling it by default on all new pipelines. Furthermore, developers can try accessing Kafka topics from Dataflow Python pipelines through an available tutorial. Lastly, according to the documentation, the billing model is not final yet.
Leave a Reply